Leading cross-team changes

There comes a time in every software company’s life where you need to make a large change to your application. This can mean introducing internationalization, improving performance, or in my case, lowering the frequency of crashes that users see in the app. The tricky part is that these large scale changes often require alignment across multiple engineering teams to achieve the desired result. This is the story of how I led cross-team engineering changes to get our crash rate under control.
Recognizing the problem
For the past four years, I’ve been responsible for Application Stability at Asana. During my first few years in this role, we operated in maintenance mode. Any time we found P0 bugs in production and bugs that blocked pushes, we’d run a 5 Whys to determine their root causes. I’d go to each of these retrospectives, and hold a check-in meeting every 6 months to reflect on the state of Application Stability with stakeholders from across engineering. In these meetings, we considered whether changes were needed. Through the end of 2016, we always decided that things were going well enough and didn’t need to change.
Then, in February 2017, I was preparing for our next check-in meeting and took a look at the following graph. It shows what percentage of our users experience a crash on a given day.
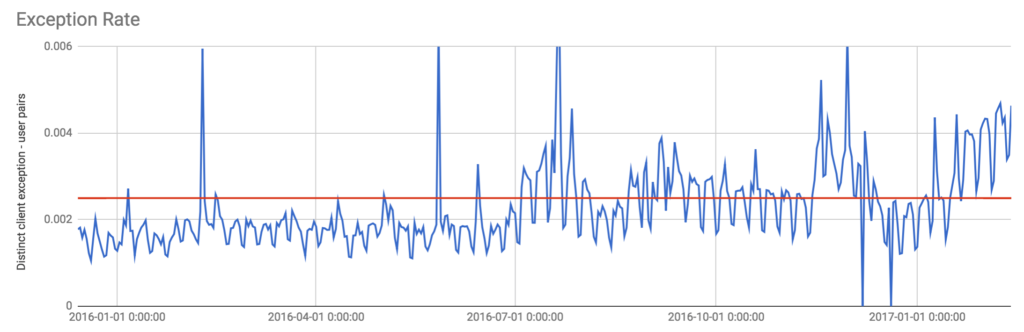
Ouch. I wasn’t expecting that uptick in July at all. At Asana, we pride ourselves on having a well-polished app that works well, and this wasn’t it. So I set out to do whatever was needed to get our crash rate back below that red line.
Setting clear goals and getting buy in
To kick off this work, I wanted to set a measurable goal (KR) to help represent the work we were doing. I also wanted a clear target so that we could celebrate if we hit our goal or reflect on what caused us to miss it if we didn’t. Setting the KR also meant that the crash rate goal would have increased visibility: it would be on the same level as our other KRs, such as hitting our feature launch goals. Elevating this work would help when thinking about tradeoffs. At the end of the day, I wanted us to “measure what matters.”
Previous experience taught me that I can’t decide on behalf of the team what goals we are committing to without getting their buy-in. In fact, I tried setting a similar KR before, but without first getting the team’s buy-in. When it came to prioritizing work, the team was surprised at the goal I had set that we hadn’t discussed before. This time around, I knew it was important to present the arguments for the work I was proposing and let the team agree to work toward the shared goal.
At first, I didn’t know how to talk to the team about this work. My emotional reaction was to blame them for introducing so many bugs, but I knew that I wasn’t going to get anywhere standing up and telling them that I was disappointed. So I reached out to my manager for coaching. He suggested that I think of this as a problem of balance. If we focus our energy on shipping features quickly, our crash rate suffers. If we focus our energy on fixing all crashes, our velocity suffers. We had focused primarily on getting things out quickly for a while, and now we needed to swing the pendulum toward stability.
This was a neat way to look at things, and I immediately felt better about tackling this problem. I used this perspective to guide me in getting everyone onboard. Now I had to come up with a plan for what I actually wanted us to do.
Planning for change
Armed with a balance-shift mindset, I worked out a plan for what we were actually changing in how we approached application stability. Here is what I proposed:
- A change in how teams decide whether to fix a bug: Before, if a bug didn’t affect 20+ users per day, we wouldn’t even look at it. Instead, I asked everyone to look at all new crashes and estimate, roughly, whether it’d be easy to fix. If it was, it should be fixed, even if it didn’t affect a lot of users.
- More aggressive rollbacks from web oncall when they found new issues in production. I also asked them to spend more time triaging crashes and assigning them to the right people. I noticed that when a bug was assigned to the right person, it got fixed faster. On the other hand, if it got assigned to the wrong person, they had no idea what to do with it, so they were more likely to just sit on it. So I asked web oncall to put more effort into triaging.
- Adding a second web oncall rotation: Because web oncall was being asked to do more work, I asked this new rotation to be the fallback for web oncall. If there was any time left, they would fix low hanging fruit from existing crashes, which would help lower the total crash count. I had to be careful, though, to make sure this didn’t become a dumping ground for all bugs. To address this, we agreed that only bugs that don’t belong to a current staffed project went to this rotation.
The team agreed to make these changes and commit to a KR, so we got to work. It was awesome to see because people really rallied around this KR and hitting the crash rate goal.
Making sure everyone knows you care
It was a bit scary setting a KR and putting my name on it when there wasn’t a staffed team behind it. Owning the KR meant I was accountable for its success, but I wasn’t doing any of the bug fixing work myself. To make up for this, I became the face of Application Stability and this KR. Even though I wasn’t doing any bug-fixing work to make it happen, everyone knew I cared. So when there was a prioritization question, everyone knew that they could talk to me. They also knew that the KR would be at risk, and that I would be disappointed if we ended up with a bad bug in production.
Celebrating together!
Where are we now? Things are still not perfect, but I’m proud of our new, far less buggy, steady state.
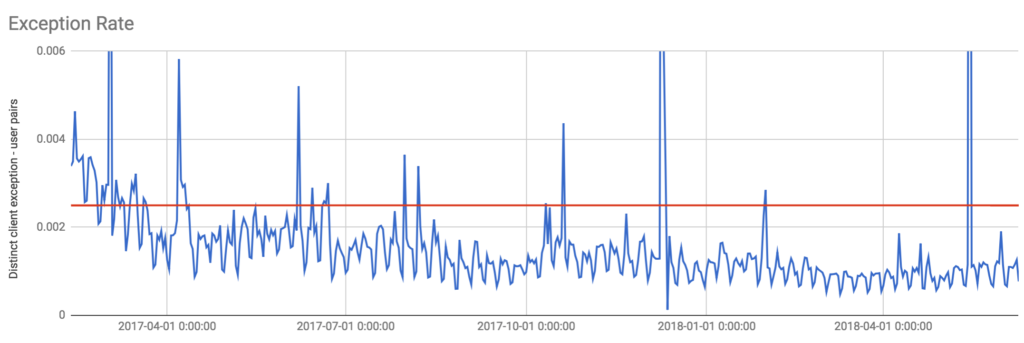
And I did this without burning any bridges:
